import re
match
从首字母开始开始匹配,string如果包含pattern子串,则匹配成功,返回Match对象,失败则返回None,若要完全匹配,pattern要以$结尾。
re.match(pattern, string[, flags])
rexg.search()
create a match object, return match objects, or re.search(pattern,stirng)
若string中包含pattern子串,则返回Match对象,否则返回None,注意,如果string中存在多个pattern子串,只返回第一个。
re.search(pattern, string[, flags])
rexg = re.complie()
create a regex object
把p的正则当成分隔符,把字符串用p进行割,最后返回
p = re.compile(r'\d+')
a_str = 'one1two2three3foure4'
print p.split('one1two2three3foure4')
===>
['one', 'two', 'three', 'foure', '']
##正则对象findall() ,来查找符合对象的字符串.以列表的形式返回
p = re.compile(r'\d+')
a_str = 'one1two2three3foure4'
print p.findall(a_str)
findall
返回string中所有与pattern相匹配的全部字串,返回形式为数组。
return s a list of stirngs,do not have the group() method, if there are more than two groups ,will return list of tuples of string,one string for each group, or re.findall(re_string, some_string)
search⇒ find something anywhere in the string and return a match object.
match⇒ find something at the _beginning _of the string and return a match object.
put the matched object in a variable, then usegroup()attribute in order to return the matched string.
import re
re_string = "{{(.*?)}}"
some_string = "this is a string with {{words}} embedded in\
...: {{curly brackets}} to show an {{example}} of {{regular expressions}}"
for match in re.findall(re_string, some_string):
...: print "MATCH->", match
we created a compiled regular expression object and used the pattern to create it. Second, instead
of calling findall() on the re module, we called findall() on the compiled regular
expression object.
>>> phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
>>> mo = phoneNumRegex.search('Cell: 415-555-9999 Work: 212-555-0000')
>>> mo.group()
'415-555-9999'
>>> phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d') # has no groups
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
['415-555-9999', '212-555-0000']
>>> phoneNumRegex = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)') # has groups
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
[('415', '555', '9999'), ('212', '555', '0000')]
group() get matched string, create with () parentheses ,group(0 or group(0) returns the full matching string
.* greedy match all the string
finditer
返回string中所有与pattern相匹配的全部字串,返回形式为迭代器。
re.finditer(pattern, string[, flags])
content = '''email:12345678@163.com
email:2345678@163.com
email:345678@163.com
'''
需求:(正则没有分组)提取所有的邮箱信息
result_finditer = re.finditer(r"\d+@\w+.com", content)
#由于返回的为MatchObject的iterator,所以我们需要迭代并通过MatchObject的方法输出
for i in result_finditer :
print i.group()
result_findall = re.findall(r"\d+@\w+.com", content)
#返回一个[] 直接输出or或者循环输出
print result_findall
for i in result_findall :
print i
需求:(正则有分组)提取出来所有的电话号码和邮箱类型
result_finditer = re.finditer(r"(\d+)@(\w+).com", content)
#正则有两个分组,我们需要分别获取分区,分组从0开始,group方法不传递索引默认为0,代表了整个正则的匹配结果
for i in result_finditer :
phone_no = i.group(1)
email_type = i.group(2)
result_findall = re.findall(r"(\d+)@(\w+).com", content)
#此时返回的虽然为[],但不是简单的[],而是一个tuple类型的list
#如:[('12345678', '163'), ('2345678', '163'), ('345678', '163')]
for i in result_findall :
phone_no = i[0]
email_type = i[1]
findall注意点:
1.当正则没有分组是返回的就是正则的匹配
命名分组和非命名分组的情况是一样的。
re.findall(r"\d+@\w+.com", content)
['2345678@163.com', '2345678@163.com', '345678@163.com']
2.有一个分组返回的是分组的匹配而不是整个正则的匹配
re.findall(r"(\d+)@\w+.com", content)
['2345678', '2345678', '345678']
3.多个分组时将分组装到tuple中 返回
re.findall(r"(\d+)@(\w+).com", content)
[('2345678', '163'), ('2345678', '163'), ('345678', '163')]
因此假如我们需要拿到整个正则和每个分组的匹配,使用findall我们需要将整个正则作为一个分组
而使用finditer我们无需手动将整个正则用()括起来group()代表整个正则的匹配
re.findall(r"((\d+)@(\w+).com)", content)
[('2345678@163.com', '2345678', '163'), ('2345678@163.com', '2345678', '163'), ('345678@163.com', '345678', '163')]
group()
A_group()_expression returns one or more subgroups of the match.
>>> import re
>>> m = re.match(r'(\w+)@(\w+)\.(\w+)','username@hackerrank.com')
>>> m.group(0) # The entire match
'username@hackerrank.com'
>>> m.group(1) # The first parenthesized subgroup.
'username'
>>> m.group(2) # The second parenthesized subgroup.
'hackerrank'
>>> m.group(3) # The third parenthesized subgroup.
'com'
>>> m.group(1,2,3) # Multiple arguments give us a tuple.
('username', 'hackerrank', 'com')
groupdict()
A_groupdict()_expression returns a dictionary containing all the named subgroups of the match, keyed by the subgroup name.
>>> m = re.match(r'(?P<user>\w+)@(?P<website>\w+)\.(?P<extension>\w+)','myname@hackerrank.com')
>>> m.groupdict()
{'website': 'hackerrank', 'user': 'myname', 'extension': 'com'}
re.DOTALL
the dot-star will match everything except a newline,By passingre.DOTALLas the second argument tore.compile(), you can make the dot character match _all _characters, including the newline character.
>>> noNewlineRegex = re.compile('.*')
>>> noNewlineRegex.search('Serve the public trust.\nProtect the innocent.
\nUphold the law.').group()
'Serve the public trust.' #only the first line
>>> newlineRegex = re.compile('.*', re.DOTALL)
>>> newlineRegex.search('Serve the public trust.\nProtect the innocent.
\nUphold the law.').group()
'Serve the public trust.\nProtect the innocent.\nUphold the law.' #all the lines
re.I
by passing the re.I as the second parameter , will ignore the case
vowe = re.compile(r'[aeiou]',re.I)
for both to use , use |
re.IGNORECASE | re.DOTALL
.*? nogreedy
import re
string = 'can me 451-777-4562 or at 545-258-5486'
phonenum = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
mo = phonenum.search(string)
print(mo.group())
phonenum = re.compile(r'(\d\d\d)-(\d\d\d-\d\d\d\d)')
mo = phonenum.search(string)
print(mo.group(1))
>>>415
? >>> \?
( >>> \(
- \* \?
python do greeding match by default ,which means match the longest string possible
{ }? put a ? after curly braces makes it dod a nogreedy match
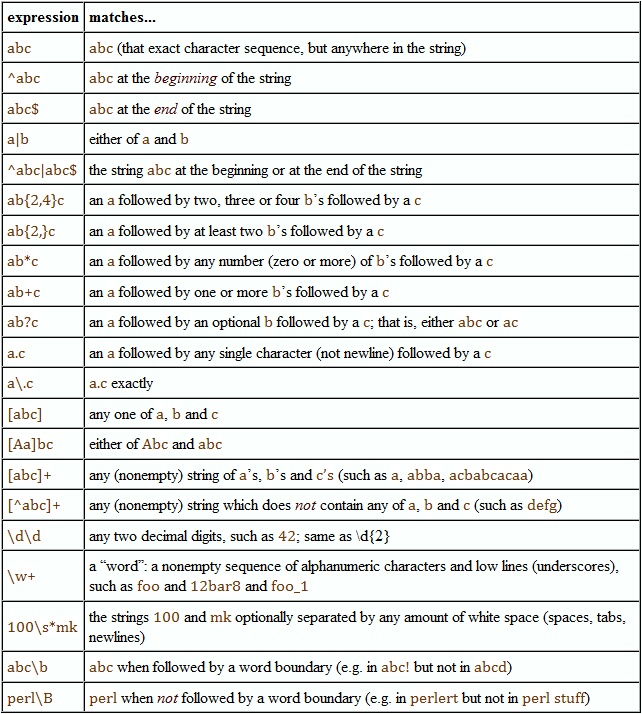

re.VERBOSE
This allowed us to write the regular expression
string in verbose mode, which simply means that we were able to split the regular
expression across lines without the split interfering with the pattern matching. Whitespace
that fell outside of a class grouping was ignored. Though we chose not to do it
here, verbose also allows us to insert comments at the end of each line of regex to
document what each particular piece of a regular expression does. One of the difficulties
of regular expressions in general is that the description of the pattern that you want to
match often becomes huge and difficult to read. The re.VERBOSE function lets you write
simpler regular expressions, so it is a great tool for improving the maintenance of code
that includes regular expressions.